The DCAM diagram for this section is:
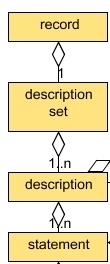
My diagram is:
If the term Dublin Core brings immediately to your mind a set of fifteen data elements, you need to try to wipe that thought out of your head. The Dublin Core Metadata Initiative (DCMI)is putting its energy today into fundamental metadata models, not any particular set of metadata elements. The most fundamental model in the DCMI suite is the Dublin Core Abstract Model (DCAM). Few outside of the small group that worked on the DCAM profess to understand it. I myself have read and re-read the DCAM document dozens of times and have still failed to have the "aha!" moment in which I would see how the DCAM explains everything of importance to metadata creation. I am, however, beginning to have some idea of what the creators of DCAM are aiming at even though I'm not yet of their world view.
It helps to understand that the Dublin Core Abstract Model defines a structure for metadata. By structure I mean something that can be acted on in a computing environment. It's not about "meaning" in the human sense of the word but about a uniformity that can facilitate the creation of programs that process the metadata. That said, having an agreement on structure is important, albeit more satisfying for machines than for humans.
The term "abstract" in the DCAM does not mean that the concepts are fuzzy or imprecise. The DCAM is very precise, in fact. It is abstract because it does not provide an actual record format for the data elements that it defines; the DCAM is concepts, not a schema or record. Yet it makes use of actual programming conventions in its definitions, such as the requirement that certain elements be represented by Uniform Resource Identifiers (URIs). The mixture of abstract concepts and programming precision is one of the things that can trip up the reader.
Another difficulty is that the DCAM is based on, and the document assumes knowledge of, the Resource Description Framework (RDF). RDF itself is poorly understood because of its own difficult concepts and obscure documentation. In this document I am not going to tackle the RDF-ness of DCAM, in part because I think that an understanding of RDF is not necessary for the implementation of metadata that takes advantage of DCAM concepts. This will be seen as heresy by some, but I liken it to natural language: we all know that we learn to speak long before we know what a "noun" or a "verb" is. In the same way, I think that we can create successful metadata without a knowledge of its deep structure, at least at an elementary level. I also think that the techniques that RDF inspires will filter out in practice, until, like language, everyone is doing it without stopping to analyze why.
Why should we bother to try to understand the DCAM? It's because the DCAM provides a neat set of metadata types that can help us communicate to each other about our metadata. It should simplify crosswalking of metadata sets, and make standards more understandable across communities. Unfortunately, it has not done so yet because it uses obscure terminology and some contorted thinking (and contains no examples). While everything in the DCAM may be absolutely as it should be, I'm going to suggest a simplified view that I think will make it accessible to more people. This simplied view will undoubtedly be seen as incorrect in some areas by the real cognoscenti of DCAM, but perhaps that can be clarified by discussion or additional documents.
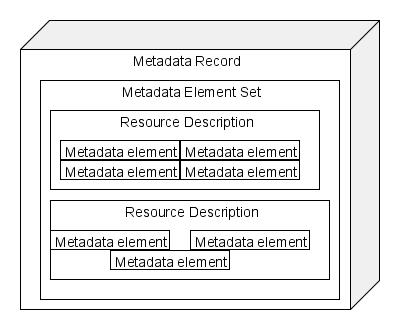
First we have the primary metadata structure hierarchy that the DCAM defines, which is that a record contains one or more description sets, each of which contain one or more descriptions, which in term contain one or more statements. Re-stating this in my words, a metadata record is a machine-readable metadata set that contains the terms that describe one or more resources.
| DCAM | Me |
|---|---|
| record | A metadata record -- the sum of all of the defined metadata elements in some machine-readable format. MARC21expressed in ISO 2709 or XML is a record in this sense. |
| description set | A group of metadata elements that is designed to describe something. For example, the fields in the MARC21 standard are a metadata set for bibliographic information. The fields in FOAF are a metadata set for "friend of a friend" data. In many cases, the fields or elements of a defined metadata standard will be a description set. |
| description | A group of metadata elements for a defined resource. In the MARC21 world we only have one description in our metadata set because our record is completely flat. FRBR suggests a different view that has multiple resources or entities, like person and topic. In a FRBR-ized view of bibliographic data there could be descriptions for each FRBR entity within our full metadata set. |
| statement | The technical definition of a metadata element. The statement defines the metadata element name (called a property) and what kind of value it can take (which I discuss below). |
The DCAM diagram for this section is: |
My diagram is: |
Now we get into the real meat -- the definitions of metadata values. I have some problems with some of the definitions here, but overall I think that this typology is useful.
The main thrust here is to define what kinds of values one can use for each metadata element. To give some examples from the MARC21 world:
Here's my attempt to define the value types that appear in DCAM:
| DCAM | Me |
|---|---|
| property URI | This is what most of us think of as the metadata term, like "title" or "date." Like everything else in the DCAM, it is identified with a Uniform Resource Identifier, a URI. |
| value surrogate | DCAM calls all of the metadata values "surrogates." In the mind of the authors, the "value" would be something in the real world, and what is in the metadata is a surrogate. I happen to accept that everything in metadata is contrived and I'm happy to call a metadata value a value. It's my opinion that adding "surrogate" to "value" just makes it harder to understand. You may wish to use my technique of just skipping over the term "surrogate" when it appears in the DCAM documentation. I honestly don't think this will lead to any mis-formed metadata. |
| literal value surrogate | This is a value that is a string of data, as I described above using the MARC21 title as an example. It's not quite that simple, however, because there are two types of literals: plain and typed. Those follow here. |
| plain value string | This is pretty much what it says: the metadata element's value will just be a plain string of characters. |
| typed value string | If you've done any programming you are probably familiar with typed values. These are things like dates, currency, numeric types (integer, long). Typed strings have the advantage that they can be checked for validity by programs. So if you have defined a metadata element as a date type of the format "yyyy-mm-dd", a program can reject any values that don't conform to that format, and editing interfaces can enforce the format when the data is created. |
| syntax encoding scheme | This refers to the rules for the typed value string above. The rule set for how your type is defined is called a "syntax encoding scheme" in DCAM, but I think of it just as a data type. An example of a data type is "gYear", one of the date data types in the W3C XML schema. The data type's identifier is what the DCAM requires. |
| non-literal value surrogate | Anything that isn't a literal string is a non-literal value. There are some very useful value types within non-literal. The basic thing to remember is that the non-literal values are all defined somewhere outside of the immediate metadata record -- in controlled lists, or perhaps through an identifier. Where plain literal values are wide open and anything goes, literal values are more controlled and therefore more amenable to computer-based quality control and accurate cross-walking. There are two essential types of non-literals: one in which there is an identifier for the value itself, and one in which the value is a combination of an identifier and a literal string. See the examples in the entries that follow. |
| value URI | This element is an identifier (URI) that identifies an actual value. One type of common value that has an identifier is a member of a controlled list, such as "http://purl.org/dc/dcmitype/Image", which is one of the values in the DCMI Type vocabulary. |
| vocabulary encoding scheme URI | This is the identifier for a controlled list. It is used by lists that don't have an identifier for each value. An example would be the ISO two- and three-letter language codes. The identifier for the ISO standard would be one element, and the the code itself would be carried as a related literal string. |
Here's a simplified diagram of the statement portion of the DCAM, based on my analysis, above:
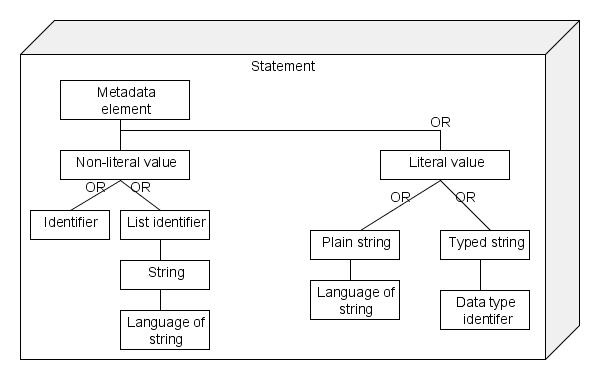
Here's the original DCAM diagram with both the macro structure (record, description set, description) and the details about statements and values. In red are the names I've given to those same terms:

You can see that my diagram doesn't include everything. In fact, by my analysis, with the exception of "value string language" all of the elements in the right-hand column are outside of the metadata record itself. (And I assume they are here by implication, not as something that would be expressed in an actual schema.) The right hand side elements are what the metadata represents. So the "described resource" is the resource the metadata is about (e.g. the item in hand), the "property" (as opposed to "property URI") is the actual attribute that is being represented by metadata (e.g. the actual book title). In other words, the DCAM includes both the "meta" and the "real," which adds to its perceived complexity. This is an aspect of the DCAM that I do not understand in terms of the functionality that this view provides. It's true that metadata is not the real thing, by definition, but I don't know why the abstract model for a metadata record would need to include both the real and the meta. I can imagine a particular metadata application including a description of the real things that the metadata represents, much as is the case with the library cataloging rules which make the connection between the item in hand and the creation of a meta representation. This is where the inclusion of the URIs in the abstract model throw me off:
The DCAM isn't much use if we can't actually do something with it. So what can we do with it? In its current state, not much, because it is only an abstract model. However, we could develop a machine-readable structure for metadata elements that follow the DCAM model. This would then allow different communities to develop metadata using the same model, and thus potentially interoperable. For example, if the library, archive and museum communities used the same model, it could be possible to share the elements that we have in common (like title and creator) while still having distinct metadata elements to meet our specific needs. The DCMI is working in this direction with application profiles, another complex set of ideas that will benefit from a little simplification.
So if you've enjoyed this explanation and want more, the full DCAM document may be just your cup of tea.
